Measuring time on task for distributed user actions
Time on task is an important metric for quantifying user behavior and motivation in software applications. However, time on task can be difficult to measure when user actions are distributed across multiple sessions. This article motivates two estimation techniques—histogramming and Kernel Density Estimation sessioning—to make time estimates on distributed user actions.

To gauge how your design is working in the wild, what metrics do you use? Do you track user satisfaction and system usability? Do you compare error and success rates against previous designs?
Have you considered the humble, yet informative, metric: time on task?
Time is ubiquitous stuff—we all experience it! It is obvious when it drags, often it seems to fly by. Maybe we just feel that we never have enough of it.
We have all experienced frustration spending too much time learning how to use a new app
Importantly, users of mobile and web applications understand how frustrating it feels to spend too much time learning to use a new app. Or how easily we can become lost in the endless scroll of social media apps and lose track of time entirely.
Given its relatively direct interpretation and utility, time on task deserves some attention. So how do we measure it?
Wibbly-wobbliness of measuring time

Measuring time on task can serve as a bellwether for the usability of our apps. But it may not be as straightforward as you imagine.
Don’t worry — the challenges you will run into measuring time shouldn’t involve those in an Einsteinian sense. But, how you measure users’ time spent on-task in your application does require approaching the problem through the mindset of a scientist.
You should approach all measurement tasks with a scientific mindset focused on validity and reliability
A few considerations should be taken to effectively measure time in a way that is valid (measuring what you think you’re measuring) and reliable (reproducible with minimized measurement error).
Those considerations fall into three broad categories:
- Building a definition of on-task behavior,
- Establishing data collection and logging aligned to our definition, and
- Choosing an appropriate mathematical model to apply to the data.

🧑💻💭 To put some context around these ideas, I will reference a current project of mine at Catalyst Education in the Labflow product. I am building a time-on-task estimation method that will allow me to measure how long teaching assistants take to grade their students’ work.
Though I will reference specific choices I made in my project, these steps are general enough to apply to other measurement problems.
1. Define on-task behavior
The first step in measuring time on task is defining what counts as evidence of the target behavior.
When I started this project, I began by articulating what “active grading time” looked like. In general, this is a step that many neglect but we must be deliberate to explain how discrete actions that a user takes align to the behavior we want to measure.
- Step 1: State in plain language the action(s) you’re trying to measure.
Example: A grader is defined as a user with the role of teaching assistant or instructor. A grader is on-task when they enter scores and comments into one of the grading interfaces and switch between student submissions, course materials, and grade book. - Step 2: Define what behaviors and behavior sequences align to the target action(s).
Example: A user with the role of teaching assistant or instructor is “actively grading” when they log in, open the grading interface, scroll and click on page elements, and then either enter or modify a score/comment for one or more students. Any actions in direct proximity to core grading actions like navigating to related resources (e.g., grade book, student submissions, supporting PDFs or rubrics) are also considered “on-task.” - Step 3: Define what behaviors and behavioral sequences DO NOT align to the target action(s).
Example: A grader is not actively grading if they do not make a modification to a score/comment in the grading interface. If the interface times out (lock screen) in proximity to grading activity, that lock screen is not included in active time on task.
Once you have made your assumptions explicit, you can then evaluate whether you are collecting that data from your application. For example, do you have the infrastructure to gather data from:
- User interactions: Scrolling & mouse clicks, page loading times, dwell time
- User events: Client side events emitted from discrete actions (e.g., clicking on button in interface, loading specific paths or pages)
- System events: Actions automatically captured between the front-end and the backend (e.g., API requests, heartbeats)
It is very important at this point to identify gaps in our data collection setup and to assess their importance. What are we missing by not having certain data points? In many cases, there are off the shelf tools and technologies that you can implement to add data collection quickly.
2. Connect on-task actions to data collection tools
The sequences of behaviors you define for each on-task action can then be mapped to triggers in your app and available data sources.
For example, here are some user behaviors and triggers I have identified that link to my definition of active grading:

It is important to recognize that this is an ideal list. You may need to resolve your wishlist with the pragmatic constraints of your project like engineering and budget constraints.
There’s a bit of an art of knowing how much data is “good enough.”
Don’t let great be the enemy of the good… unless good equates to non-random gaps in your data collection
Just beware that incomplete data is, well, incomplete. Gaps in data can happen, but as long as the blind spots are random, then you can get off the ground quickly with only some of these data sources operating.
⚠️ Revisit your assumptions regularly
If gaps in data are concentrated in certain user segments, entire routes of your app, or times of the day it is not random and should not be ignored.
For example, if you set up more robust data collection for your mobile vs. web users, you should not then make claims about differences in time spent between these groups.
3. Choose a mathematical model
🎉 Congratulations! Getting to this point is a big deal.
So how do we then take a slew of discrete observations from user and system interactions and turn them into a measure of time on task?
🤖 Naïve Model: Stopwatch time ⏱️
The simplest models to implement are what I refer to as stopwatch time.
Stopwatch time makes minimal assumptions and only measures how long a stopwatch would run uninterrupted from the first to the last event in a series of on-task actions.
Stopwatch time measures the total elapsed time from the first to last event in a sequence of behaviors

Stopwatch time is simple and easy to implement. If we can identify the first and last instance of a behavior, subtracting yields total time.
Stopwatch time can be improved by pairing it with outlier and threshold assumptions:
- Set a maximum amount of time that a user can be on-task (thresholding)
- Remove extreme values from your time estimates (outlier detection)
- Replace extreme values with the group mean (transformation)
💪 Strengths and limitations
However, even with post-processing techniques stopwatch models tend to only be useful when user activity is concentrated, i.e. users complete an action in a single sit down session or timeframe.
In natural settings, humans take breaks! We get up and walk around, check our social media feeds, and then maybe return to the task when we feel our ability to concentrate has returned.
Unfortunately, this all but guarantees that stopwatch time will overestimate how long users spend on-task. No thresholding, outlier removal, or data transform can solve that problem.

🤖 Model 1: Histogramming 📊
How can we improve on the naive approach of the stopwatch model, especially when dealing with distributed activity?
One way to improve estimates over a naive model would be to computationally segment time into clusters of activity. With the clusters identified, we could compute time spent in each cluster of behaviors.
Finding burst of activity in distributed user actions is a 1D clustering problem

So how to find those clusters? One option is the histogramming technique.
It makes use of an affordance of how time is represented in computer systems. Computer logging systems use standardized data types (DATETIME and TIMESTAMP) to mark the time when a record was created or updated.
The predominant web standard is the ISO 8601 date format. Here it is specified as year, day, month, 24-hour time down to the partial second, and a time zone designation:
2022–09–27T17:34:06.514ZTimestamps that are dated after 1970 can also be transformed into their Unix epoch, which is the number of seconds that have transpired since midnight Jan. 1, 1970 in Coordinated Universal Time (UTC). This same timestamp can then be equivalently written:
1664300046With times converted to an integer value, epochs can then be binned in a histogram like any other continuous interval measure.

The critical insight now is that the width of each bin is a unit of time (in seconds). The number of bins then gives you an estimate of how many time increments were spent on task!
⚠️ Calibrating the bin size
Setting the width of the histogram should be done carefully both to produce clusters on your data and to leave space where there is no activity.
If your bin width is set too narrowly, you will overestimate how much inactive time your user had between bursts of activity. Conversely, if the bin you select is too wide, you will over estimate on-task behavior by washing out meaningful time periods between moments of user actions.
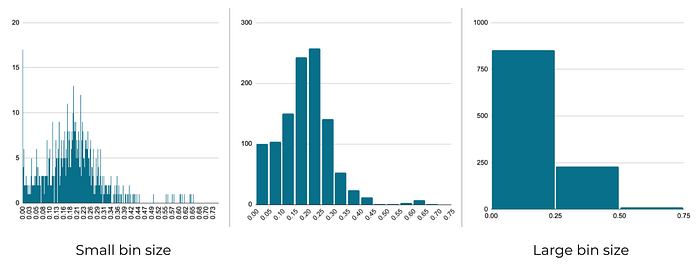
The bin size should also be calibrated to the desired resolution of your estimate. For example, if the task you want to measure happens relatively quickly, it might be appropriate to set your bin size to 10 or 30 second increments.
Most distributed activity, though, is likely to stretch out across a broader range of time. So perhaps a 5, 10, or even 30 minute bin size is appropriate.
Ultimately the bin size you choose will be the smallest resolution you can achieve in your estimate. That is, for a 30 minute bin, you’ll only be able to estimate time on task to the nearest 30 minutes. For a finer grained resolution, narrow the bin size.
💪 Strengths and limitations
This technique is easy to implement and can be done in a number of different technologies. My favorite place to implement this is directly into my SQL queries and bypass the need for processing the raw data outside of my database call.

🤖 Model 2: Sessioning with Kernel Density Estimation (KDE) 🔔
The histogramming approach marks a significant improvement over the naive model, but one of its limitations is overestimation when observations fall on hard histogram bin boundaries.
To improve this approach, I looked for a model that would solve the hard-boundary problem of histograms and I landed on Kernel Density Estimation (KDE).
KDE is a computational method that uses a kernel basis function (e.g., gaussian, exponential, Epanechnikov) to model a density plot that would arise from a set of point observations.
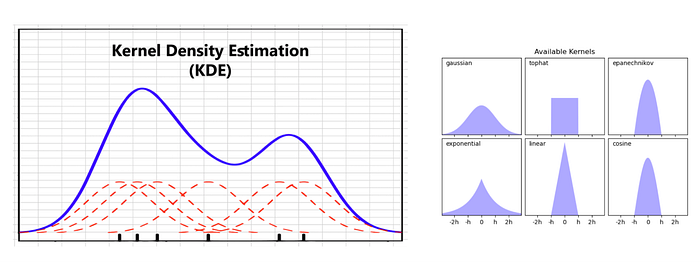
The kernel functions are centered on each observation and the resulting kernel density is the linear sum of those parameterized point observations.
Gaussian kernels are often used in KDE because they have the property that their linear sum is a function that has continuous first- and second-order derivatives.
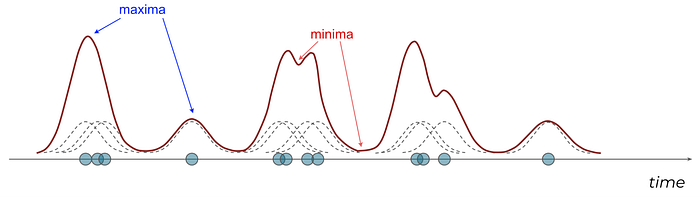
Importantly, the KDE reaches a local maximum around clustered observations. Similarly, local minima correspond to regions of low density in the data.
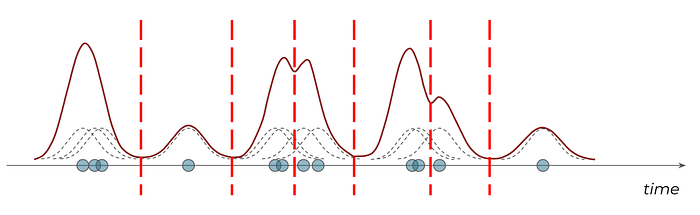
What makes this technique useful for time on task estimation is that these minima align to a logical boundary between distinct groups of user actions (it tells us how to segment our clusters!).
Local minima mark the segmentation points between local clusters of user actions!
The time between the first and last action in each cluster then gives us a much more refined estimate of elapsed time within an activity cluster.
The sum of the elapsed time in each cluster that we designate on-task then gives us an estimate of total time spent!
⚠️️ Bandwidth size
Like with the histogramming technique, KDE kernels have a width parameter called their bandwidth. Setting this parameter will define how many clusters appear in your data.
If your bandwidth is too narrow, it will overfit your data, produce too many segmentations, and overestimate inactive time. If the bandwidth is too wide, it will produce too few clusters and overestimate on-task behavior.

Setting your bandwidth to the hypothesized timescale of your users’ behavior is important here, but you will not run into the problem of your bandwidth dictating measurement precision.
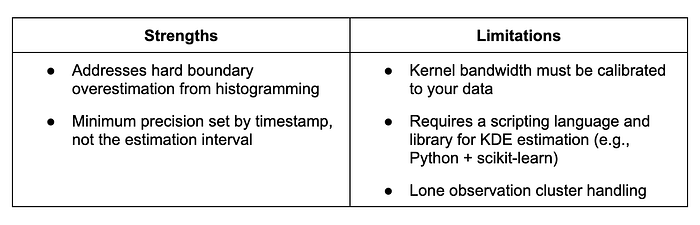
💪 Strengths and limitations
The KDE model, while more precise, does require more computational resources and additional technologies (e.g., Python, ML library) in your technology stack to get working.
One limitation of the KDE approach is how to handle lone observation clusters. In the histogramming model, each observation is associated with a bin that then contributes to the final time estimate. In sessions found by KDE, we require at least two points to define the start and end of user behavior.
How can you handle lone observation clusters?
- Drop them! They may just be noise and not meaningful to include
- Assign an alternate minimum time value
⛔️ If you have a high count of lone observation clusters, you should rule out that the your bandwidth is set too narrowly. Modify your bandwidth to be bigger and see if your count of lone observations improves.
🤔 How do the time estimates compare to users’ self-reports?
To know if these models were performing well, I also collected some measures of ecological validity: users’ self-reports.
I wanted to know do these estimates line up with how long people estimate report spending on a task?
I asked two participating instructors at a partner university to agree to time themselves grading in a naturalistic setting (i.e., grade as normal). They were asked to start a timer when they were grading and pause it when taking breaks.
I then collected their self-report data and computed both the histogramming and KDE sessioning estimates for three separate weeks of the course.
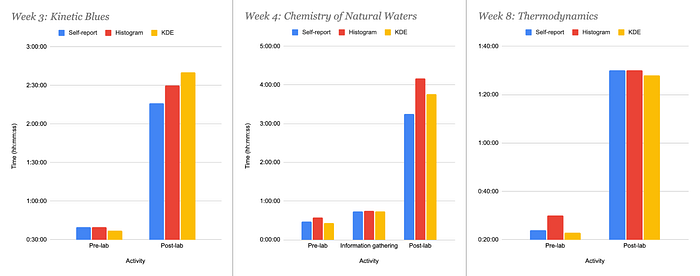
The graph presents this data chronologically for multiple activities each week. Each cluster of bars shows the grading time data for a single activity.
Self-report time is on the left (blue 🔵), histogramming estimate is in the middle (red 🔴), and the KDE sessioning estimate is to the right (yellow 🟡).
What we can see is that, in general:
- Estimates were close in all cases, deviating at most around 15–30 minutes.
- Histogramming was more likely to overestimate than KDE
Note: The instructor who graded Week 4 of the course reported that they forgot to time themselves grading the post-lab. This also coincides with the biggest discrepancy between self-reports and model estimates.
🔮 Conclusion & future work
By analyzing time on task data, researchers can gain a deeper understanding of user behavior and user needs, especially when we see something that looks out of the ordinary.
I proposed a general framework for starting with a definition of what on task action you want to measure, establishing a measurement infrastructure for capturing that data, and then some useful mathematical models to turn observations into a time estimate.
The models we got a look at were stopwatch time, histogramming, and KDE sessioning. Each has their own strengths and limitations, so deciding what is appropriate for you and your use case is an important conversation to have with product and engineering stakeholders.
As part of my evolving work on this, I plan to share some usable code snippets to get your team up and running with accurately estimating time on task.
Disclaimer: These writings reflect my own opinions and not necessarily those of my employer.
